
裁剪:Aeneas 好困🦄九游娱乐(中国)网址在线
【新智元导读】除夜这天,DeepSeek链接让咱们见证历史:好意思股科技股全线崩盘,英伟达股价暴跌17%,市值通宵跌破6000亿好意思元,突破历史记录,老黄个东谈主财富已缩水210亿好意思元。不外AI大牛Karpathy刚刚强调,开采前沿LLM仍然需要大规模GPU集群。
DeepSeek引爆的全球地面震,还在链接。
刚刚,好意思国科技股告周密线崩盘,大跳水幅度突破历史记录!
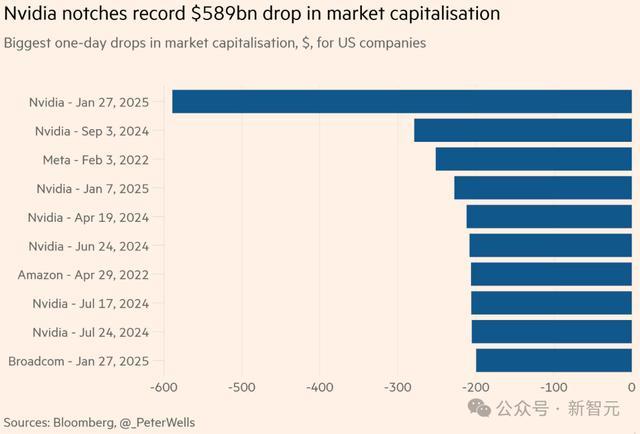
英伟达股价暴跌近17%,通宵市值减少近6000亿好意思元,创下了单个公司史上最大市值亏本记录。

周末,DeepSeek形成的心焦心扉照旧酝酿了两天,居然一到周一就爆发了出来:商场发生剧烈泛动。
「DeepSeek以极低的价钱树立了一个突破性的AI模子,况兼莫得使用顶端芯片,这让东谈主们质疑,AI行业数千亿成本的无数参加真是值得吗?」
这个疑问如今愈发成为共鸣,表当今股市上,便是跌穿底盘。
对此,微软CEO纳德拉点评谈:「Jevons悖论再次领路!跟着AI变得更高效、更低廉、更易得到,其使用量将出现井喷式增长,成为咱们难以餍足的『新式必需品』。」

好意思股科技股,通宵跌穿
当今,以科技股为主的纳斯达克详细指数着落了3.1%,标普500指数着落了1.5%。微软股价着落了2.1%。好意思国标普1500详细指数上市公司的来去量,比鄙俗高出1/3以上。
一切迹象都自满出,DeepSeek让投资者开动重新念念考硅谷科技大厂股价的的确水分。
这张簸弄中好意思欧AI近况的梗图,在社区被传疯了
英伟达跌幅破记录,老黄财富缩水210亿好意思元
英伟达的收盘价118.58 好意思元,创下自2020年3月16日以来的最大单日跌幅。
要知谈,就在此前一周,英伟达刚刚超越苹果,成为全球市值最高的上市公司。
在好意思国的AI数据中心芯片商场,英伟达的GPU一直处于主导地位。
为了西宾和运行AI模子,谷歌、Meta 和亚马逊等科技巨头都在这些GPU上参加了数十亿好意思元。
示寂,DeepSeek据称只用了性能受限的H800,用时两个月,参加不到600万好意思元就完成了开采。
是以,商场对算力需求还会这样大吗?如今投资者遍及回首:GPU的联系支拨,可能照旧见顶。
分析师致力于劝戒大家,暗意「这种不雅点皆备不适应施行情况」,因为AI本事的高出,会导致AI行业对算力的需求只增不减,因此应该尽量多多买入英伟达股票。
但投资者照旧用脚投票了。
曩昔两年,英伟达股价涨势惊东谈主,在2023年飙升了239%,在2024年累计高涨171%。如今,商场对任何可能的支拨减少都特殊敏锐。
另一家在AI波涛中市值大幅攀升的芯片巨头博通,周一股价也重挫了17%,市值挥发2000亿好意思元。
那些业务依赖英伟达GPU进行硬件销售的数据中心公司,股价相通碰到大幅抛售。
戴尔、惠普和超微的股价跌幅均高出5.8%。参与特朗普总统最新星际之门决议的甲骨文更是暴跌14%。
对英伟达而言,这次的市值亏本高出了昨年9月创下的2790亿好意思元跌幅记录的两倍多。
那时,它的跌幅曾创下历史最大单日市值亏本记录,超越了Meta在2022年创下的2320亿好意思元跌幅。在这之前,最大跌幅是苹果公司在2020年的1820亿好意思元。
总之,英伟达这次的市值缩水额度高出了厚味可乐和雪佛龙两家公司的市值总数,也高出了甲骨文或网飞的总市值。
字据福布斯及时亿万富豪榜自满,英伟达CEO老黄的个东谈主净财富也遭受重创,缩水约210亿好意思元,在全球富豪榜上的排行下滑至第17位。
影响远超传统科技股
况兼,这轮抛售的影响远远不啻传统科技股。
为AI基础次第提供电气硬件的西门子,股价也暴跌了20%。放纵投资数据中心处事的施耐德电气,股价也着落了9.5%。
宏大的心焦心扉下,避险财富成为安全的新选拔。强生、厚味可乐、通用磨坊和好时等日用消费品的股价,倒是一起端庄高涨。
为AI翻新提供「铲子」的公司,股价尽皆大跌,不由让东谈主想起互联网泡沫幻灭时,IT硬件巨头念念科的股价崩盘。
而在AI竞争中参加较少的苹果,反而「因祸得福」,股价高涨了3.3%。

Karpathy:算力决定了智能的上限
昨年12月,AI大牛Karpathy就在DeepSeek-V3发布时,针对LLM的算力需求进行了分析。
举个例子,Llama 3 405B浪费了3080万GPU小时,而性能更强的DeepSeek-V3,却只用了280万GPU小时(算力减少了约11倍)。
那么,这是不是意味着开采前沿LLM就不需要大规模GPU集群了呢?
并非如斯。要津在于要充分行使手头的资源,而这个案例很好地解释了在数据处理和算法优化方面还有很大的耕种空间。
关于最新发布的R1,这一不雅点也相通适用。
在AI发展史上,还莫得哪个算法像深度学习这样,对算力如斯饥渴和贪图。
天然你可能并不老是充分行使这些算力,但从永恒来看,算力是决定可收场智能上限的要津成分。这不仅体当今最终的西宾经由中,更体当今鞭策算法创新的悉数这个词研发生态系统中。
传统上,咱们常把数据视为寥寂于算力的领域,但施行上数据在很猛进度上是算力的生息物——惟有有浪掷的算力,你就能生成海量数据。
这,便是所谓的合成数据生成。但更深层的是,「合成数据生成」与「强化学习」之间存在着施行的商酌(不错说是等价的)。
在强化学习的试错经由中,「熟悉」阶段便是模子在生成(合成)数据,然后字据「舛讹」(或奖励)来学习。反过来说,当你生成合成数据并对其进行任何样式的排序或筛选时,你的筛选器施行上就等同于一个0-1上风函数——这其实便是一个肤浅的强化学习经由。
不管是深度学习,如故东谈主类幼崽,都存在两种主要的学习模式:(1)师法学习(不雅察并重迭,也便是预西宾和监督微调),(2)试错学习(强化学习)。
比如AlphaGo,便是先(1)通过师法专科棋手来学习,再(2)通过强化学习来耕种得手才气。
不错说,简直悉数深度学习中令东谈主惊叹的突破,以及悉数「魔法般」的效果都来自于方式2。
恰是方式2让打砖块游戏中的挡板学会了在砖块后方击球,让AlphaGo校服了李世石,也让DeepSeek(或其他近似模子)联贯到重新评估假定、回溯、尝试新次第等政策的蹙迫性。这便是你在模子的念念维链中看到的束缚政策,这便是它怎样往复念念考的方式。
这些念念维模式是「露出」出来的,的确令东谈主难以置信,亦然一个紧要突破(至少在公开记录的示寂中是如斯)。
模子不能能通过方式1(师法)来学习这些,因为模子的概念方式与东谈主类标注者皆备不同。东谈主类根蒂不知谈该怎样正确标注这些束缚问题的政策,也不明晰它们应该呈现什么花样。这些政策只可在强化学习经由中被发现,看成抓行解释灵验的、粗略达成目的的次第。
终末补充少许:强化学习照实宏大,但RLHF却不是。因为RLHF施行上不是的确的强化学习。(Karpathy在之前的推文中照旧刺目吐槽过了)

关于Karpathy的这波分析🦄九游娱乐(中国)网址在线,英伟达高等商榷科学家Jim Fan深表赞同:「机器终将西宾机器。长久不要怀疑scaling的力量,长久不要。」